
The future of AI is local, but the path to get there is hidden by "Hardware Blindness." Stop guessing which users can run your models. Start auditing their silicon.
ReactBooster enables you to ship high-performance Web AI at a fraction of the cost by moving execution from expensive cloud GPUs directly to your users' NPUs and GPUs.

.png)
In 2026, users don’t just browse; they interact with Agentic AI - systems that personalize layouts in real-time and process data on-device. ReactBooster bridges the gap between your AI models and the metal.
The shift to Local-First Web AI is the defining trend of the year. Processing models locally using WebGPU and Wasm slashes latency and eliminates massive server costs.
Static templates are obsolete. 2026 is about Generative UI - layouts that adapt their structure, color palettes, and CTAs based on real-time user behavior and intent.
Users now talk, gesture, and look at their screens to navigate. This Multimodal Interaction requires near-zero INP (Interaction to Next Paint).
Running AI models locally is the ultimate goal for minimizing latency, but it creates a high-stakes trade-off.
High-end models offer "instant" local inference but require immense processing power.
Without intelligent gating, local inference locks the main thread, causing frozen UIs and browser crashes.
Developers are often forced to choose between "Cloud-only" (high latency/high cost) or "Local-only" (excluding 50% of their mobile audience).
Before you ship a single weight or tensor, use the Silicon Matrix Report to map the "AI Readiness" of your actual traffic. Stop building for an "average" device that cannot handle your models.
We analyze Javascript, WebGPU, and WASM AI performance to indicate which specific models (LLMs, Diffusion, Vector Embeddings) your users can actually run locally today.
Know exactly what % of your users support WebGPU or WASM-SIMD before you spend months on a technical architecture that only works for a fraction of your audience.
Locate your High-End Device users. These are the devices sitting on untapped NPU power - identify them to unlock "Pro" features without increasing your cloud OpEx.
Once the Matrix identifies your hardware segments, the ReactBooster Engine dynamically routes every inference request to the optimal execution path.
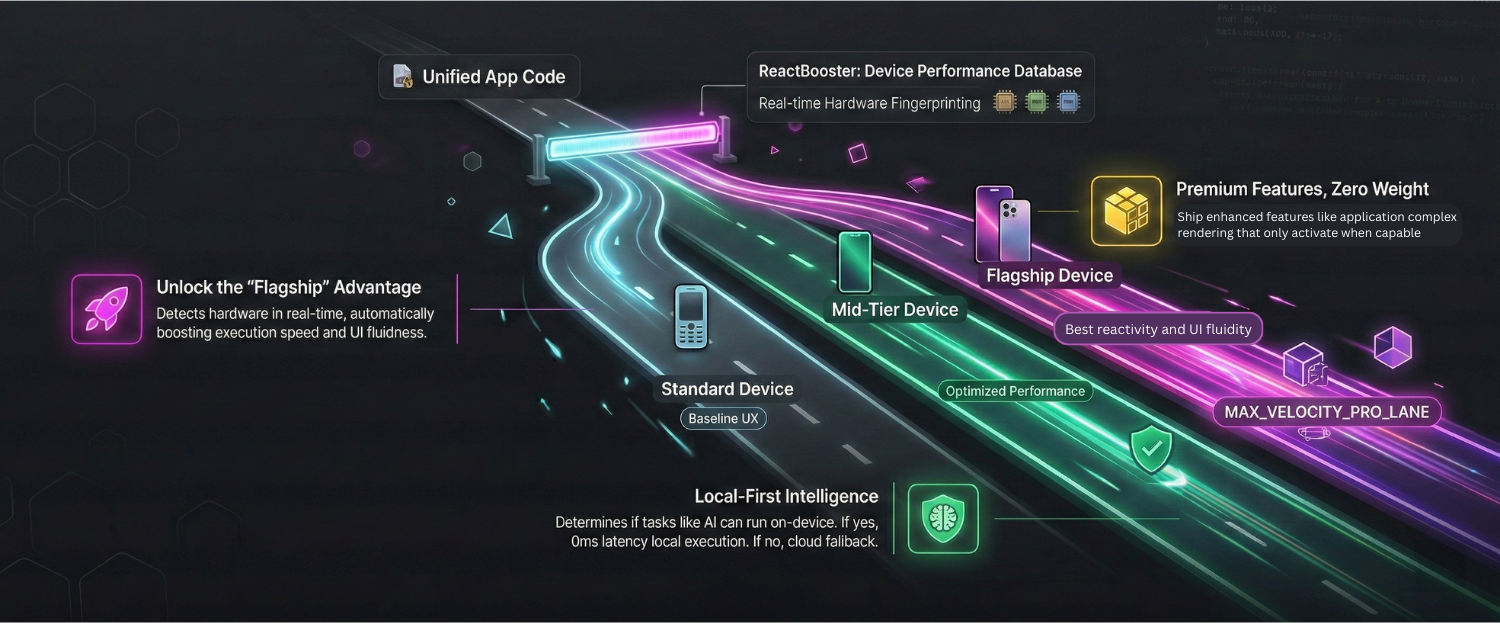
If a user is Flagship Device user, the engine initializes a local WebGPU worker for instant, zero-cost inference. If they are Legacy, it transparently falls back to your cloud API to prevent a browser crash.
ReactBooster moves 100% of AI model loading and execution into background threads. Your UI stays "Buttery Smooth" and responsive (Elite INP) even while a 7B parameter model is generating text locally.
Serve "Lite" quantized models to mid-tier devices to ensure broad reach, while unlocking full-precision "Pro" models for your flagship users.
We utilize the SpeedPower.run engine to execute real-world saturation benchmarks directly on the user's hardware. This data - representative of a modern, heavy web application - calculates the Silicon User Device Capability Score at the heart of the Silicon Matrix.
Instead of guessing based on static model names or theoretical hardware specs, we measure the 'True Usability' of the silicon. By stress-testing the device’s ability to handle concurrent processing, Edge-AI tasks, and main-thread saturation, we identify exactly how much 'Real-World Room' your application actually has. We don't just see the device, we see its pulse.
Performance is not just a technical metric, it is a direct multiplier for your bottom line. ReactBooster turns engineering excellence into your strongest competitive advantage.
By utilizing Local Execution on capable hardware, ReactBooster offloads massive compute requirements to the user’s device. Reduce your cloud API and server costs by up to 60%, allowing you to scale your Web AI features without scaling your monthly bill.
Search engines and AI crawlers prioritize the fastest, most stable sites. By maintaining a perfect Speed Index and Core Web Vitals, you become the preferred source for AI Search Agents like Perplexity and OpenAI, ensuring your products are the first to be recommended.
ReactBooster eliminates the cognitive friction that leads to cart abandonment. When your site feels as responsive as a native app, you build a "habit-forming" shopping experience that increases Customer Lifetime Value (CLV) and turns one-time shoppers into brand advocates.

Speed is revenue. Ensure product filters and "Add to Cart" actions respond instantly (INP). By slashing latency, you improve your Speed Index and create a frictionless checkout flow that captures intent before it fades.

First impressions are everything. We eliminate the loading friction that kills conversions, optimizing your Time to Interaction to ensure your message reaches the user immediately and maximizes the ROI of every marketing dollar.

Engagement depends on proximity. We move logic to the edge to accelerate Time to Play for media and ensure your site loads faster for every user. Whether in New York or Tokyo, deliver a premium "local-feel" experience worldwide.

Trading requires split-second precision. ReactBooster ensures live tickers and complex charts update without lag. Using our Devices Database, we maintain elite CWV and instant responsiveness—crucial for making trades when every millisecond counts.
Uncover the untapped hardware headroom on your users' devices. Our Silicon Matrix Report identifies exactly where your architecture redlines and calculates the projected ARR you can reclaim by eliminating main-thread jank.
Powered by ScaleDynamics
© 2026 ScaleDynamics. All rights reserved.
Contact Us: contact@scaledynamics.com
Privacy Policy | Legal Information